Are you getting lost in the ever-changing world of AI chatbots? Tired of trying to figure out which tool is right for you? I was, but discovered Chatbot Arena. It’s a free crowdsourced service that helps you put AI models to the test. Discover which tools will support your needs. Best of all, you can compare the outputs from different models.
What is Chatbot Arena?
Chatbot Arena is a project from LMSYS.org that allows people to compare and evaluate different AI tools and chatbot software. The platform provides side-by-side comparisons of various AI tools.
Although Chatbot Arena is known as a benchmarking tool, it also offers a host of benefits even for beginners. If you’re new to large language models (LLMs), you might think only a handful exist, such as ChatGPT, Claude, Bard, Llama, etc. These are some of the more familiar models from organizations like OpenAI, Anthropic, Google, Meta, etc.
But, if I look at the recent LMSYS Chatbot Arena Elo Leaderboard, there are 58 models. Part of this is because there can be multiple models with similar names:
- Claude-1
- Claude-2.0
- Claude-2.1
- Claude-Instant-1
The service has compiled some useful information within its tables and tabs. This is even before we start providing our prompts to test various LLMs. Let’s take a high-level look at the Chatbot Arena Leaderboard.
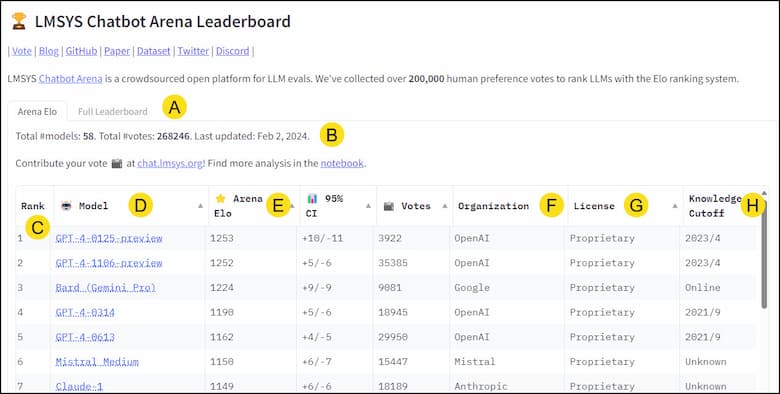
[A] These tabs let you switch between Arena Elo and the Full Leaderboard. Both tabs provide descriptive and quantitative information.
[B] Indicates the number of models and update date. The date is not updated in real time.
[C] The model’s rank based on its Elo score. You can sort the table by column values by clicking the small triangle. For example, clicking Organization will group like entities. I find this useful if I want to find all OpenAI’s models etc.
[D] The model name. If you click the name, you’ll be taken to a page that discusses the model although it may be a press release.
[E] Arena Elo and CI are evaluation scores. The CI is the Confidence Interval. Elo is an evaluation method that is similar to how chess players are judged. In simple terms, each test has some assigned points. The winning model gets those points added to their cumulative score. In contrast, the loser gets those points subtracted.
[F] The organization that produces the model.
[G] The model’s license type.
[H] How current is the model’s source data. This can be a critical factor based on your query. For example, you couldn’t expect GPT-3.5 Turbo to know about events that occurred after September 2021.
Creating Comparison Test Prompts
While you can enter any prompt into the tool, it’s best to think about how you plan to use the text AI tools. Each model has its properties that could impact the answer. For example, not all models will allow you to upload a file for analysis. If that’s your case you may need to create an account with the specific service and buy a plan.
The goal is to create a test suite of prompts that you plan to use over time. This allows you to see how the different models have evolved. The type of prompts you create should align with your needs and cover different areas. For example, if you’re a marketing analyst you might think of prompts that relate to:
- Defining buyer personas
- Data analysis and insights
- Sentiment analysis & customer service responses
- A/B Testing ideas
And if you’re stumped about the type of testing prompts, ask the models for help. Or, you can try building a prompt from a template.
Different Battle Scenarios
One feature I appreciate about the tool is its two “battle” modes. The first mode is the Arena Battle. This is where your prompts is answered by Model A and Model B. However, you don’t know the model names until you click a button at the bottom. Then the model names appear.
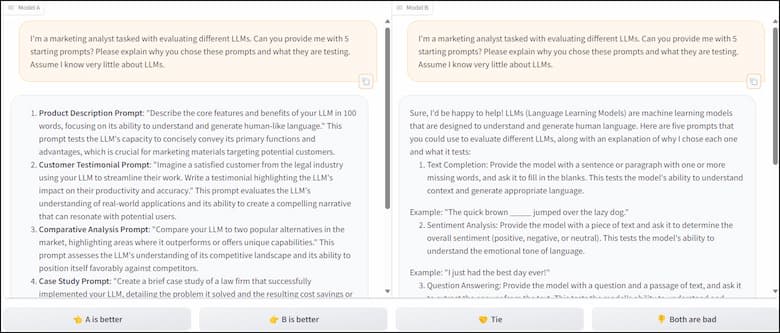
Use Chatbot Arena Battle (Anonymous Models)
- In your browser, navigate to https://arena.lmsys.org/
- Click OK on the popup that indicates this is a research preview.
- Scroll down the page till you see a textbox that reads, “Enter your prompt and press ENTER“.
- Enter your prompt.
- Click the Send button.
- Read the results and click the appropriate button.
You should now see the name of the LLMs used for the battle.
Use Chatbot Arena (side-by-side)
Another battle type that can be more rewarding is the side-by-side comparison. Instead of the system assigning two random LLMs, you can choose which two to test. This is the method I prefer because some models don’t suit my needs. I much prefer doing my own pairings.
- Go to https://arena.lmsys.org/
- Click OK to the research preview popup.
- Click the top tab labeled “Arena (side-by-side)“.
- Click in the field showing the model name.

- Select your model name from the drop-down list. You can also clear the field and start typing letters.
- Scroll down and enter your prompt.
- Click Send.
- Review the responses.

- Cast your vote using the buttons at the bottom.
If you don’t like the responses, you can click the Regenerate button that is below the voting buttons.
Rinse and Repeat
If you plan to evaluate these models over time, you might want to save the prompts and replies. For example, I store my prompts in TextExpander so I can reuse by typing their shortcuts. You’ll notice that on both prompt and response, there is an icon so you can copy and paste information. Using the same prompt will make it easier to track results over time. You’ll need to devise your method as the system doesn’t save your information.
Two items you do need to be aware of are sharing and timing. The Share button creates a .PNG file but it may not include everything based on the length of the reply. I initially thought I could save a link to the test and share it with others.
I also noticed that the page can timeout if inactive. This happens if I wait too long to do the next test. I’ll either get some sort of communication timeout or JSON error.